728x90
hierarchical clustering
계층적 군집화(Hierarchical Clustering)
- 개체들을 가까운 집단부터 순차적/계층적으로 차근차근 묶어 나가는 방식
- 유사한 개체들이 결합되는 dendogram 을 통해 시각화 가능
- 사전에 군집의 개수를 정하지 않아도 수행가능
- 모든 개체들 사이의 거리에 대한 유사도 행렬 계산
- 거리가 인접한 관측치끼리 cluster형성
- 유사도 행렬 update

학습 과정
Hierarchical Clustering 를 수행하려면 모든 개체들 간 거리(distance)나 유사도(similarity)가 이미 계산되어 있어야 합니다.

이표는 A와 D의 거리가 가까워서 cluestring 을 한다.
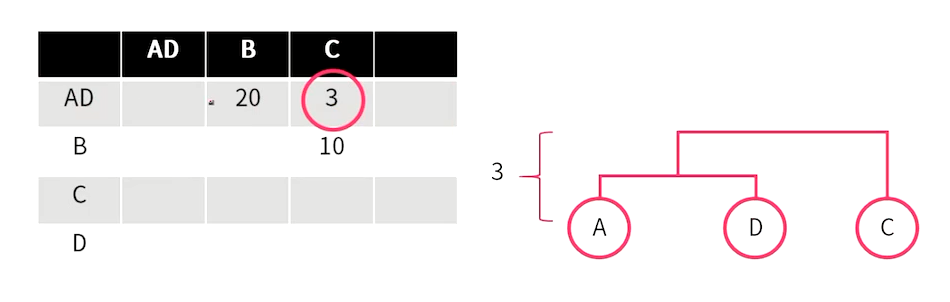
AD군집과 가장 가까운 거리는 C라는것이라고 해서 묶어서 새로운 cluester로 할당을 하는것이다.
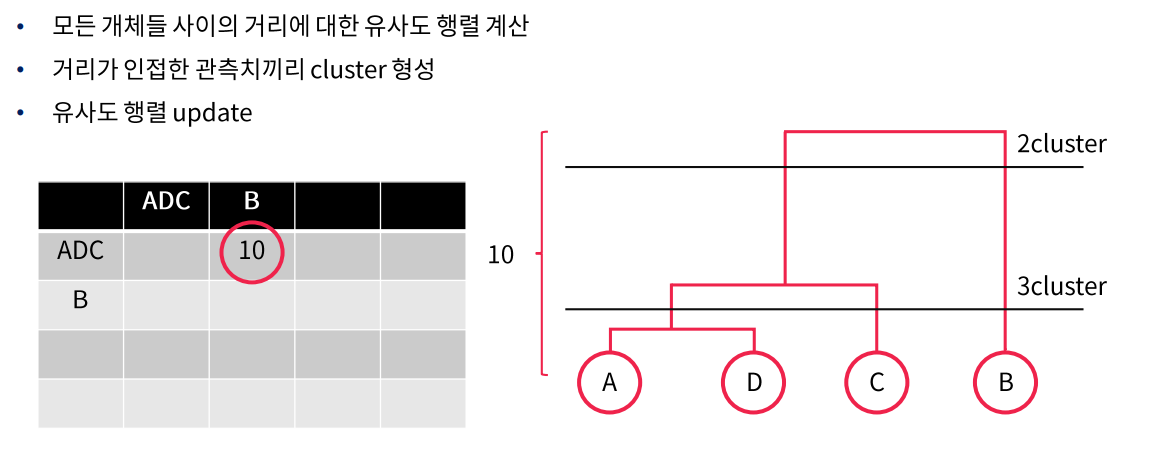
마지막으로 adc를 b와 묶어서 표현을 한다.
마지막으로 총 4개로 볼수있다.
한 군집으로엮었으면 거리행렬을 바꾸어주어야합니다. 다시 말해 개체-개체 거리를 군집 개체 거리로 계산해야 한다는 것입니다.
‘AD’와 ‘B’, ‘AD’와 ‘C’ 이렇게 거리를 구해야 한다는 말입니다. 그런데 군집-개체, 혹은 군집-군집 간 거리는 어떻게 계산해야 할까요? 여기엔 아래 그림처럼 여러가지 선택지가 존재합니다.
Cluestering 간의 거리

데이터간의 거리로 하였는데 나중에는
군집간의 거리를 구하는것이기때문에 이거를 얘기를 하고있다.
최소점
최대점
모든데이터간의 거리를 평균
군집간의 중앙점에 대한 거리
이 4가지 를 제일 많이 사용합니다
그리고 .

728x90
'ML > 머신러닝' 카테고리의 다른 글
| 머신 러닝 - cost Function (0) | 2022.06.20 |
|---|---|
| 머신러닝 - logistic classificaction (0) | 2022.06.20 |
| 머신러닝 Minimize cost (0) | 2022.06.20 |
| 머신 러닝 - 기본 용어 및 개념 (0) | 2022.06.16 |