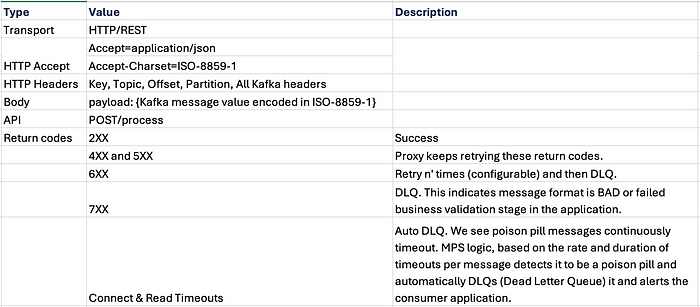
아파치 카프카란 무엇인가?
한마디로 말 하자면 Data inMotion platform이라고 말할수 있습니다.
즉, 움직이는 데이터를 처리하는 플랫폼이라고 하면서 또 다른 말로 하자면 Event Streaming Platform 이라고 합니다.
실시간으로 흐르는 이벤트를 받아서 데이터가 필요한곳으로 데이터를 전송해주는것!

Event는 비지니스 상에서 흐르는 모든 일들을 (Data)을 의미합니다.
예시로는
- 우리가 웹 상에서 클릭
- 송금
- 청구서 발행
- 위치정보
- 택시 GPS, 배달 기사분들의 실시간 위치
- 센서의 온도/압력 데이터
이러한 Event의 특징은 BigData의 특징을 가지고있습니다.
- 비지니스 모든 영역에서 광범위하게 발생
- 대용량의 데이터가 발생
끝임없이 데이터가 들어오기 때문에 event stream 이라고 부르고있습니다.
LinkedIn 회사는 세계적인 구인구직 회사입니다.
- 하루 4.5조 개 이상의 이벤트 스트림 처리
- 하루 3000억개의 사용자 관련 이벤트 스트림 처리
LinkenIn 내의 요구사항 중 이렇게 많은 사람들의 정보가 왔다갔다 하는데 무슨일이 일어나는지에 대해서 실시간의 정보를 알고싶었습니다.
그 당시 사용했던 MQ 로 처리가 불가능했습니다. 그래서 링크드인 개발자가 이벤트 스트림 처리를 위해 개발한것이 Apache Kafka입니다.
카프카는 LinkendIn 회사에서 개발을 시작해서 Apache Kafka를 오픈소스화 하면서 2011년부터 커뮤니티에서 발전을 하였습니다.
LinkedIn 회사의 개발자인 Jay Kreps, Neha Narkhede, Jun Rao 분들에 의해서 개발이 되었고
<추후에 Confluent 회사를 설립해서 카프카의 발전을 지속적으로 해옴>

왜 카프카 라고 지었을까?
- Jay Kreps가 명명
- Kafka는 쓰기(Write) 에 최적화된 시스템이기 때문에, 작가(Writer)의 이름을 사용하는 것이 의미가 있다고 생각했고, 대학에서 문학 수업을 많이 들었으며 그가 좋아했던 Franz Kafka의 작가의 이름에서 따왔습니다.

Apache Kafka 에 3가지 주요 특징
1. 이벤트 스트림을 안전하게 전송 (Pub & Sub)
2. 이벤트 스트림을 디스크에 저장(Write to Disk) - 기존 아파치 카프카 이전 솔루션과 아파치 카프카 구분하는것 큰 특징은 대용량 데이터를 디스크에 writing 하면서 대용량 데이터를 전송하는데 엄청난 처리량을 제공
3. 대용량의 처리가 가능하기에 이벤트 스트림을 분석 및 처리가 가능해졌습니다.
얼마나 많은 회사들이 사용하고 있을까?
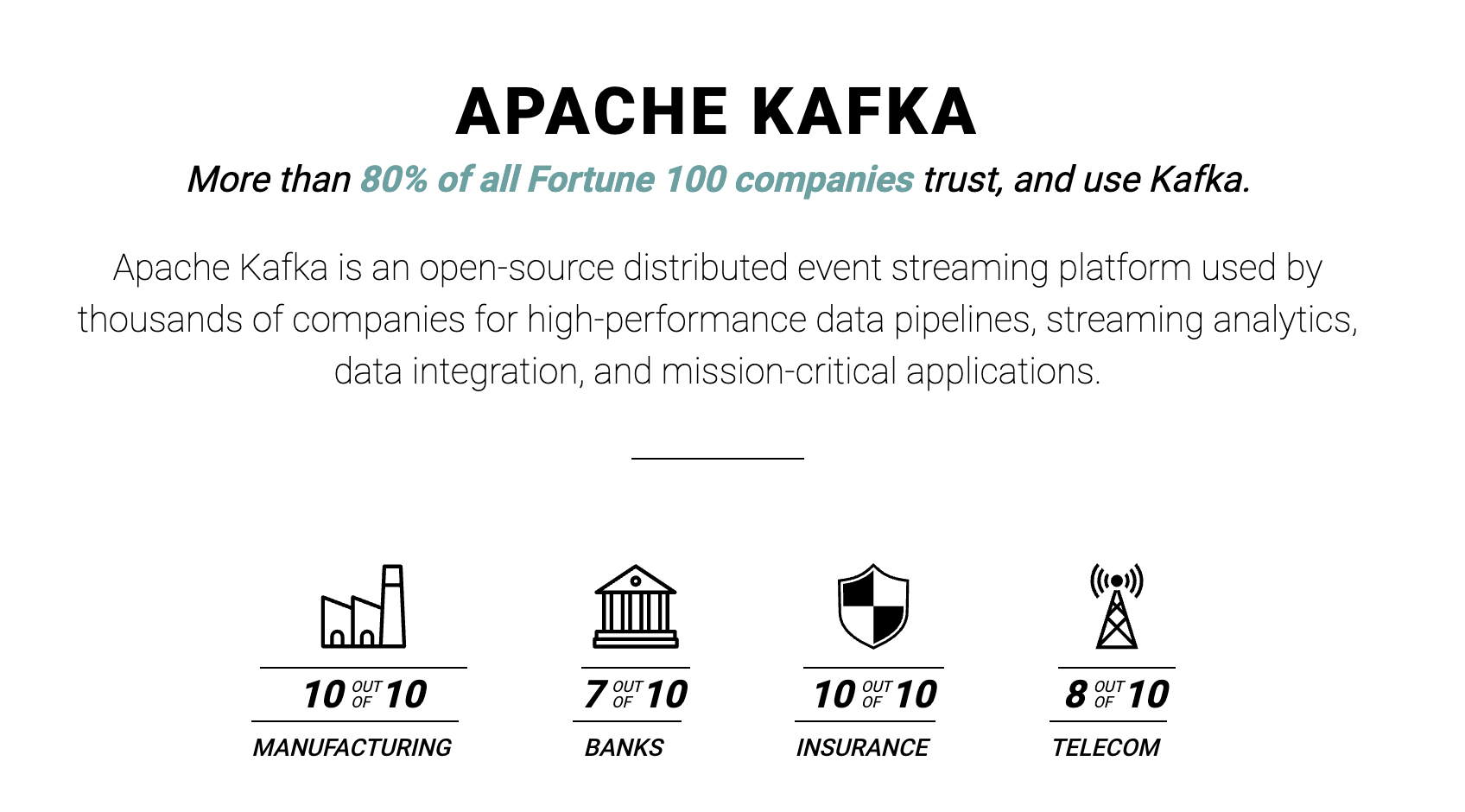
Fortune 100기업 중 80% 이상이 사용하고 있습니다.

국내의 기업들은 최소 102개의 기업에서 사용중에 있습니다.
아파치 카프카의 사용사례는?
Event(메시지/데이터)가 사용되는 모든곳에 사용이 가능
- Message System(중간 매개체)
- IoT 디바이스로부터 데이터 수집
- App에서 발생하는 로그 수집도 가능
- 이상거래탐지/중복거래
- 사기 방지 목적으로도 가능합니다.(한국은 2014년 이후로부터 모든 금융거래에 FDS(Fraud Defence System)을 의무 도입해야되면서 실시간 탐지시스템 솔루션이 많이 생겨났습니다.)
- DB 동기화(MSA 기반의 분리된 DB간 동기화)
- 서비스를 많이 쪼개놓으면서 db또한 쪼개놓아서 많이 쓰이면서 나눠진 데이터를 동기화 해야되는 경우
- 고객정보 같은 경우 A 서비스와 B 서비스를 join 해야되는 경우 원장 테이블을 다른 테이블에 복제해서 사용할때 사용합니다.
- 실시간 ETL (Extract, Transform, Load)
- ETL 프로세스는 데이터 분석, 비즈니스 인텔리전스(BI) 및 보고서를 위해 데이터를 통합하는 데 필수적입니다. 이 과정을 통해 기업은 여러 출처의 데이터를 하나의 시스템에서 관리하고 분석할 수 있습니다.
대표적 사례들
| 교통 | 금융 |
| 운전자 - 탑승자 매치 도착예상시간(ETA) 업데이트 실시간 차량 진단 |
사기 감지, 중복 거래 감지 거래, 위험 시스템 모바일 App, |
Why Apache Kafka?
다른 유명한 Rabbit MQ 혹은 apache Storm(twitter 개발) 이 있는데 아파치 카프카를 사용할까?
예전에 벤치마킹을 했을때 기존의 MQ 와 같은 성능 보다 월등하게 데이터를 처리하는것을 보았습니다.
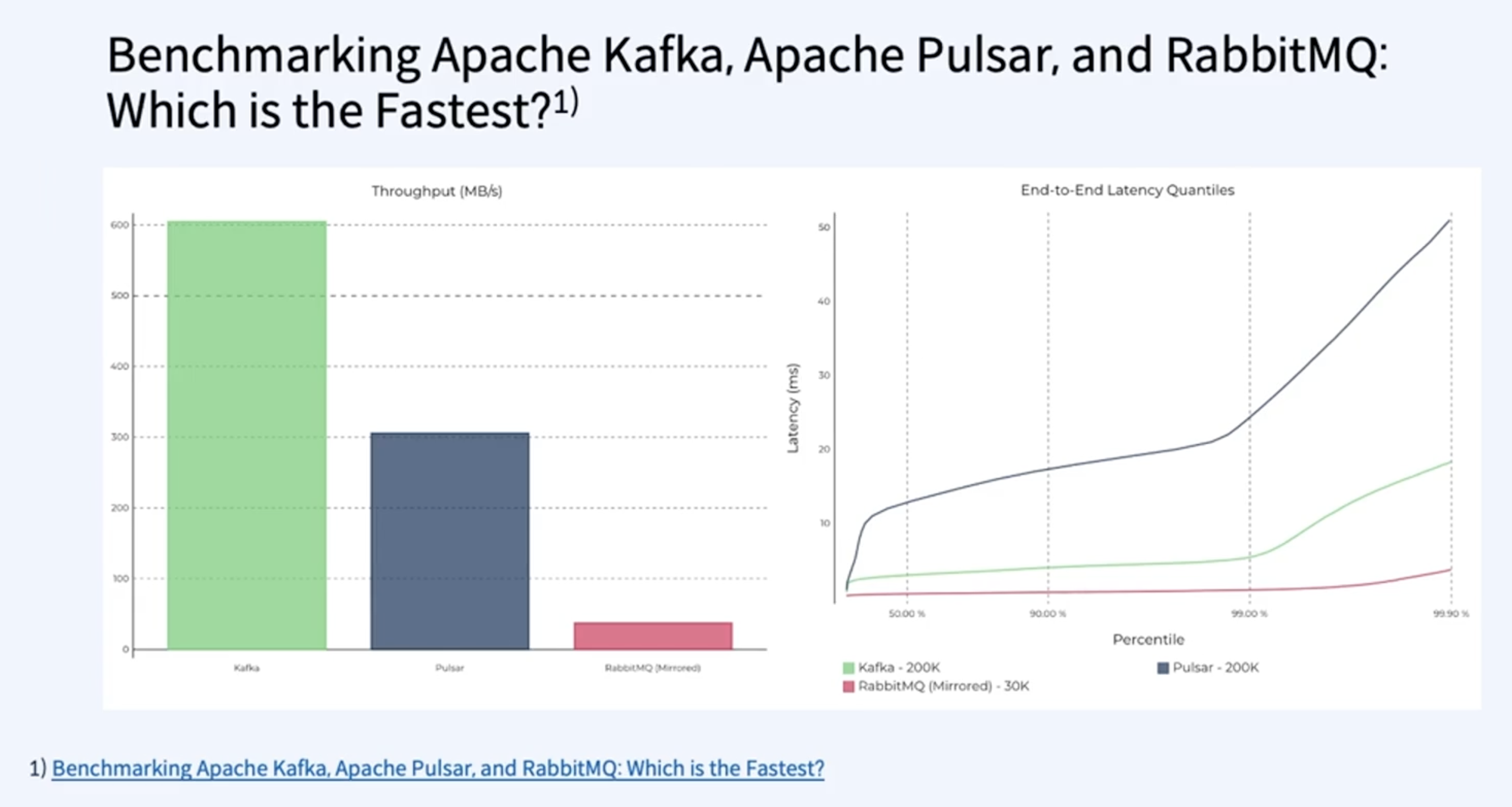
그래프가 높으면 높을수록 더 좋은 성능을 나타내고 오른쪽은 낮을수록 좋다는것을 나타내는 지표입니다.
MQ와 비교했을때 큰 차이를 나타냅니다. 30k와 200k의 차이점 그리고 95%의 데이터를 5milisecond에 처리합니다.
Apache Kafka® Performance, Latency, Throughout, and Test Results
Benchmark Apache Kafka performance, throughput, and latency in a repeatable, automated way with OpenMessaging benchmarking on the latest cloud hardware.
developer.confluent.io
Benchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines)
I wrote a blog post about how LinkedIn uses Apache Kafka as a central publish-subscribe log for integrating data between applications, stream processing, and Hadoop data ingestion. To actually make this work, though, this "universal log" has to be a cheap
engineering.linkedin.com
카프카의 짧은 스토리와 왜 많은 기업들이 카프카를 선택했는지에 대해서 짧게 알아보았습니다.
그렇다면, 이제 간단하게 카프카의 기능들에 대해서 알아보도록 하겠습니다.
기본기

★ Producer
메시지를 주제(topic)에 게시하는 클라이언트는 프로듀서라고 합니다. 프로듀서는 특정 파티션에 메시지를 기록합니다. 이는 메시지 키와 파티셔너를 사용하여 키의 해시를 생성하고 이를 특정 파티션에 매핑함으로써 이루어집니다. 기본적으로 프로듀서는 메시지를 모든 주제의 파티션에 고르게 분배합니다. 그러나 경우에 따라 프로듀서는 특정 파티션으로 메시지를 직접 보낼 수 있습니다. 이는 메시지 키에 특정 파티션 스킴을 적용하여 달성됩니다.
★ Consumer
소비자는 구독한 주제에서 메시지를 끌어와 읽습니다. 소비자는 파티션에 기록된 순서대로 메시지를 읽습니다. 소비자는 메시지 오프셋을 사용하여 자신의 소비를 추적합니다. 소비자가 특정 메시지 오프셋을 확인하면, 이는 소비자가 해당 파티션에서 그 오프셋 이전의 모든 메시지를 수신했음을 의미합니다.
소비자는 소비자 그룹의 일원으로 작동하며, 하나 이상의 소비자가 함께 주제를 소비합니다. 이 그룹은 각 파티션에 대해 하나의 소비자만 책임지도록 설계되었습니다. 예를 들어, 다음 그림에서는 네 개의 파티션(p0, p1, p2, p3)과 세 개의 소비자(c0, c1, c2)를 가진 메시지 주제가 있습니다. 가능한 파티션-소비자 매핑은 다음과 같습니다: c0는 p0, c1은 p1과 p2, c2는 p3입니다.
이 둘의 특징 :
Producer 와 Consumer는 서로 알지 못하며, Producer와 Consumer는 각각 고유의 속도로 Commit Log에 Write및 Read를 수행합니다.
다른 Consumer Group 에 속한 Consumer들은 서로 관련이 없으며, Commit Log에 있는 Event(Message)를 동시에 다른 위치에서Read 할수 있습니다.
여기서! Commit Log는 무엇인가?
Commit Log : 추가만 가능하고 변경이 불가능한 데이터 structure, 데이터(event)는 항상 로그 끝에 추가 되고 변경되지 않습니다.
Offset : Commit Log에서 Event의 위치 122번째 의 offset을 볼수 있습니다.
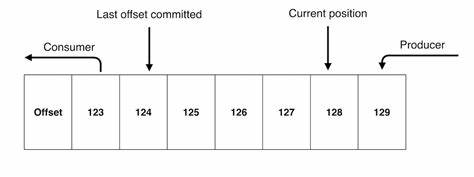
카프카도 commit Log 라고 하는 개념으로 만들어져있습니다.
Producer 가 Write하는 LOG-END-OFFSET과 Consumer Group의 Consumer가 Read 하고 처리한 후에 Commit한 CURRENT-OFFSET과 차이(Consumer Lag)가 발생 할 수 있습니다.
★ Topic
- 카프카 안에서 메시지가 저장되는 장소, 논리적 표현
- Partition : Commit Log, 하나의 Topic은 하나의 파티션으로 구성, 병렬처리(Throughput 향상)를 위해서 다수의 partition 사용
- segment : 메시지(데이터) 물리파일 - 저장되는 실제 물리 File , segment file이 지정된 크기보다 크거나 지정된 기간보다 오래되면 새 파일이 열리고 메시지는 새 파일에 추가됨
실제 Physical view를 보게 되면
Topic 생성시 Partition 개수를 지정하고, 각 partition은 broker들에 분산되며 Segement File들로 구성되게 됩니다.

파일을 Rolling 하여 분리/생성합니다.
Rolling Strategy : log.segment.bytes(default 1 GB), log.roll.hours(default 168 hours)
용량을 정하거나 시간을 가지고 파일을 시간에 맞춰 분리 시키면서 롤링하는것이 카프카의 구조입니다.
★ broker
게시된 메시지는 브로커라고 불리는 일련의 서버에 저장됩니다. 브로커는 프로듀서로부터 메시지를 수신하고, 오프셋을 할당한 후 이를 디스크에 기록합니다. 또한 소비자의 메시지 가져오기 요청에 응답하여 서비스를 제공합니다.
★ cluster
카프카 브로커는 클러스터의 일원으로 작동합니다. 클러스터 내에서 한 브로커는 클러스터 컨트롤러 역할을 하며, 이 컨트롤러는 관리 작업을 담당합니다.
카프카에서는 복제를 통해 파티션 내의 메시지에 대한 중복성을 제공합니다. 따라서 브로커가 실패할 경우, 팔로워 중 하나가 리더십을 맡을 수 있습니다. 모든 프로듀서는 메시지를 게시하기 위해 리더에 연결해야 하지만, 소비자는 리더 또는 팔로워 중 하나에서 메시지를 가져올 수 있습니다.
클러스터 내에는 파티션을 소유한 단일 브로커가 있습니다. 이 브로커를 파티션의 리더라고 합니다. 복제된 파티션은 추가 브로커에 할당되며, 이들은 파티션의 팔로워라고 불립니다.
여기까지 기본적인 카프카의 간단한 기능을 알아보았습니다.
* 출저 :
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
https://developer.confluent.io/learn/kafka-performance/
'글또' 카테고리의 다른 글
| 안정적으로 메시지 처리하는 카프카 (7) | 2024.10.13 |
|---|