안녕하세요, 랭체인이 작년부터 Hot해지고 서서히 여러사람들에 알려지고있는거같습니다.
또한, 요즘 AI 트렌드에 따라 국내 많은 회사들이 랭체인을 사용해서 AI 챗봇을 만들고 있는것으로 알고있습니다.
랭체인에 접하시진 얼마 안되신분들을 위해 좋은 자료를 공유해보도록하겠습니다.
기본적인 RA(Retrieval-Agumented Generation)에 기본적으로 알고 계신다는 전제 하에 글을 적어보도록 하겠습니다.

우리가 알고 있듯이 단순 검색 증강 생성 즉 RAG는 2단계 프로세스를 통해 최종 결과를 생성하는데요, 먼저 쿼리를 임베딩 벡터로 변환한 다음, 미리 계산된 벡터 데이터베이스에 대해 유사성 검색을 수행하여 가장 관련성이 높은 문서를 검색하게됩니다.
관련성이 있는 문서를 검색한 후 RAG 시스템은 해당 콘텐츠를 원래 쿼리와 병합하여 종합적인 데이터 세트를 형성합니다.
그런 다음 이 데이터 세트는 LLM 모델에 의해 처리되어 쿼리에 대한 문맥상 관련성이 높은 응답을 생성하게 됩니다.
간단한 RAG 방법의 최종 결과는 쿼리 작성 방식에 따라 달라집니다. 쿼리 구문의 사소한 변화로도 결과가 달라질 수 있습니다.
이러한 강력한 쿼리 의존성을 완화하고 결과의 일관성을 향상 시키기 위해 다중 쿼리 리트리버 방법이 개선된 솔루션으로 나왔습니다.
이 방법은 초기 쿼리에 대해 검색된 단일 문서 세트에 의존하여 최종 결과를 생성하지 않습니다.
대신, 원래 쿼리에 대한 다양한 해석을 기반으로 여러 문서 세트를 검색함으로써 다양성의 힘을 활용하게 됩니다.
이는 모호하거나 부정확하게 공식화된 쿼리를 처리할 때 특히 유리합니다. 이 방법은 여러 쿼리를 통해 더 넓은 그물을 던짐으로써 방대한 문서에서 가장 관련성이 높고 정확한 답변을 찾아낼 가능성을 현저히 높입니다.
이 간단한 글에서는 LangChain 프레임워크에 있는 멀티쿼리 리트리버 메서드를 활용하는 방법을 살펴보겠습니다.
여기에 제시된 코드는 LangChain에서 제공하는 예제에서 가져온 것입니다. 마지막으로 LangSmith 플랫폼에서 생성되는 다양한 단계와 출력을 관찰하고 검토해 보겠습니다.
! pip install langchain_community tiktoken langchain-openai langchainhub chromadb langchain
import os
import bs4
from langchain_community.document_loaders import WebBaseLoader
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_openai import ChatOpenAI
from operator import itemgetter
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnablePassthrough
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_openai import ChatOpenAI
from langchain.load import dumps, loads
## Environment Variables
os.environ['LANGCHAIN_TRACING_V2'] = 'true'
os.environ['LANGCHAIN_ENDPOINT'] = 'https://api.smith.langchain.com'
os.environ['LANGCHAIN_API_KEY'] = 'YOUR_API_KEY'
os.environ['OPENAI_API_KEY'] = 'YOUR_API_KEY'
# this is optional, before using this line, create a project with this name in the langsmith
os.environ['LANGCHAIN_PROJECT']='multiquery-retriever'
환경 변수 설정하기 :
환경에서 필요한 모든 라이브러리를 설치하는 데 문제가 발생했는데, 특히 윈도우 에서 pwd 라이브러리를 사용할 수 없기 때문에 문제가 발생 했습니다. 따라서 리눅스 환경에서 코드를 실행하려고 시도했습니다.
다음 단계는 환경 변수를 설정하는 것입니다.
먼저 전체 워크플로우를 모니터링하기 위해 오픈AI 의 LLM(대규모 언어모델)과 랭스미스를 활용하기 때문에 LangSmith API 키와 OPEN AI API 키를 획득하는 것이 중요합니다.
LANGCHAIN_PROJECT 변수는 선택사항입니다. LangSmith 플랫폼에 기존 프로젝트가 있는 경우 LangChain_PROJECT 변수에 해당 프로젝트 이름을 지정할 수 있습니다. 이 변수가 없으면 기본 프로젝트가 자동으로 생성됩니다.
데이터 로드 및 청크 생성 :
여기서는 WebBaseLoader를 사용하여 HTML 웹페이지의 텍스트를 문서 형식으로 가져옵니다.
사용 가능한 데이터 소스에 따라 PDFLoader 와 같은 대체 데이터 로더를 활용할 수 있습니다.
로딩 후에는 RecursiveCharacterTextSplitter를 사용하여 문서를 청크로 나눕니다.
여기서는 HTML 웹페이지의 텍스트를 문서 형식으로 로드하기 위해 WebBaseLoader를 사용하고 있습니다. 데이터 소스에 따라 PDFLoder와 같은 다른 로딩 라이브러리를 사용할 수 있습니다. 그런 다음 로드된 문서는 RecursiveCharacterTextSplitter를 사용하여 청크로 분할됩니다.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
blog_docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=300,
chunk_overlap=50)
# Splitting the document
splits = text_splitter.split_documents(blog_docs)
임베딩 및 인덱싱 :
RAG(검색 증강 생성) 프로세스 중 임베딩 단계에서는 문서의 텍스트를 의미론적 의미를 캡슐화 하는 숫자 벡터로 변환됩니다. 여기에서 변환은 시스템이 내용을 파악하고 대조하는 데 도움이 됩니다. 그런 다음 색인 단계에서는 이러한 임베딩을 검색 가능한 데이터베이스 내에 체계적으로 배열하여 유사성 측면에서 쿼리 벡터와 가장 근접한 문서를 신속하게 식별하고 검색할 수 있도록 합니다.
제공된 코드 스니펫은 벡터 저장소를 사용해 리트리버를 설정하는 데 도움이 되며, 임베딩 함수에는 OpenAIEmbeddings()가 사용됩니다.
vectorstore = Chroma.from_documents(documents=splits,
embedding=OpenAIEmbeddings())
retriever = vectorstore.as_retriever()
다중 쿼리 프롬프트 :
다른 핵심 단계는 원래 질문을 기반으로 여러 개의 쿼리를 개발하는 것입니다. 이를 위해 프롬프트와 ChatOpenAI를 사용하여 주어진 질문의 다섯 가지 버전을 만드는 것을 목표로 합니다.
# Multi Query: Different Perspectives
template = """You are an AI language model assistant. Your task is to generate five
different versions of the given user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user question, your goal is to help
the user overcome some of the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines. Original question: {question}"""
prompt_perspectives = ChatPromptTemplate.from_template(template)
generate_queries = (
prompt_perspectives
| ChatOpenAI(temperature=0)
| StrOutputParser()
| (lambda x: x.split("\n"))
)
LangChain 표현 언어를 사용하면 여러 단계로 구성된 시퀀스를 구성할 수 있습니다. "|" 연산은 이러한 단계를 정의된 순서로 구조화하는 데 매우 중요합니다.
def get_unique_union(documents: list[list]):
""" Unique union of retrieved docs """
# Flatten list of lists, and convert each Document to string
flattened_docs = [dumps(doc) for sublist in documents for doc in sublist]
# Get unique documents
unique_docs = list(set(flattened_docs))
# Return
return [loads(doc) for doc in unique_docs]
# Retrieve
question = "What is task decomposition for LLM agents?"
retrieval_chain = generate_queries | retriever.map() | get_unique_union
# Tesing a single retriever
# docs = retrieval_chain.invoke({"question":question})
# len(docs)
마지막으로, 지정된 쿼리에 대한 결과를 생성하기 위해 최종 체인을 활성화할 준비가 되었습니다.
처음에는 5개의 서로 다른 쿼리 중 하나에 해당하는 5개의 개별 문서 세트를 검색한 다음 이를 결합합니다.
이 집계 후 언어 모델은 결합된 문서를 처리하여 출력을 생성합니다.
template = """Answer the following question based on this context:
{context}
Question: {question}
"""
prompt = ChatPromptTemplate.from_template(template)
llm = ChatOpenAI(temperature=0)
final_rag_chain = (
{"context": retrieval_chain,
"question": itemgetter("question")}
| prompt
| llm
| StrOutputParser()
)
final_rag_chain.invoke({"question":question})
## here is the output generated
#Task decomposition for LLM agents refers to the process of breaking down complex tasks into smaller and more manageable subtasks. This allows the LLM-powered agent to efficiently handle and solve complex tasks by dividing them into smaller steps. Task decomposition can be achieved through various methods, such as using simple prompting, task-specific instructions, or incorporating human inputs.
이제 각 단계를 검토/모니터링하고 랭스미스(LangSmith)를 사용하여 결과를 확인할 차례입니다. 시작하려면 LangSmith 계정에 로그인하고 프로젝트 영역으로 이동합니다. 여기에서 아래에 설명된 대로 모든 단계와 그 결과물을 확인할수 있습니다.

각 검색기(Retriever)는 백터 데이터베이스에서 독립적으로 문서 세트를 검색하며, 특정 사례에는 5개의 고유한 문서 세트가 포함됩니다.

마지막으로 모든 문서가 통합되고 결과를 생성하는 것으로 llm이 종료됩니다.
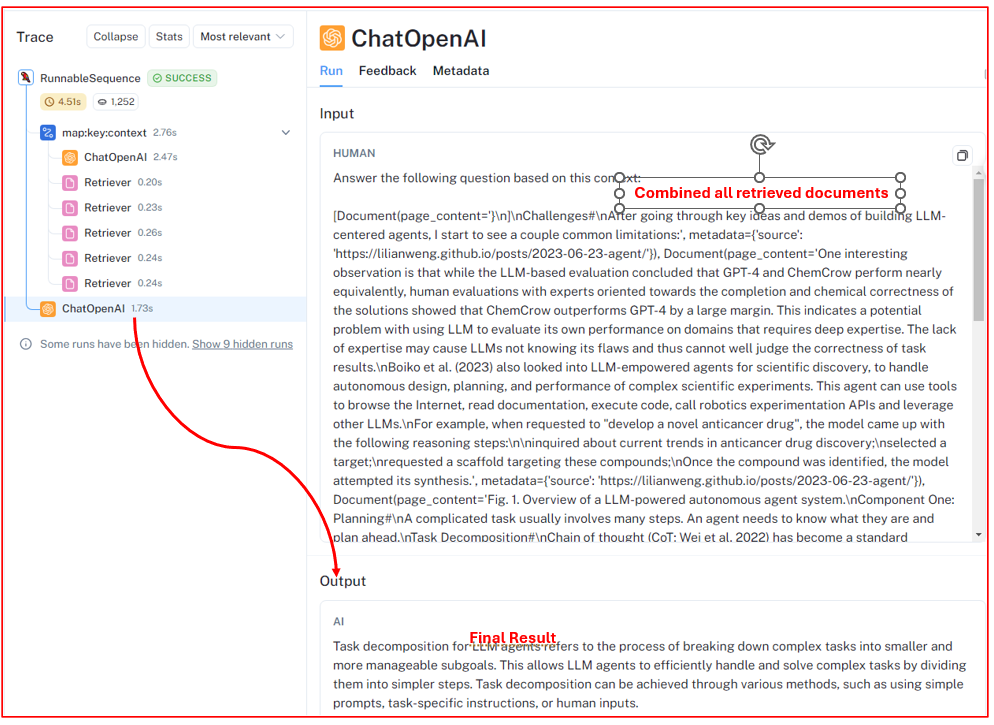
이 문서에서 다중 쿼리 리트리버 접근 방식을 살펴보면서 이 방식을 구성하는 여러 단계에 대해 자세히 살펴봤습니다.
이 접근 방식은 초기 쿼리에 대해 검색된 단일 문서 세트에 의존하여 최종 결과물을 생성하지 않기 때문에 기존의 RAG 전략에 비해 크게 개선된 방식입니다. 대신, 원래 쿼리에 대한 다양한 해석을 기반으로 여러 문서 세트를 검색하여 다양성의 힘을 활용합니다.
이는 모호하거나 부정확하게 공식화된 쿼리를 처리할 때 특히 유리합니다.
이 방법은 여러 쿼리를 통해 더 넓은 그물을 던짐으로써 방대한 문서에서 가장 관련성이 높고 정확한 답변을 찾아낼 가능성을 현저히 높입니다.
출처 : Advanced RAG: Multi-Query Retriever Approach | by Kamal Dhungana | Medium
'LangChain' 카테고리의 다른 글
| Prompt Leaking(프롬프트 공격) (0) | 2024.05.28 |
|---|---|
| Langchain 과 SerpApi 로 챗봇의 웹 기능 강화 (0) | 2024.05.16 |
| 프롬프트 예시들 (0) | 2024.04.05 |
| 일반적인 프롬프트 설계 (0) | 2024.04.05 |
| 프롬프트의 기초 (0) | 2024.04.05 |