
엘라스틱서치
전문 검색을 지원하기 위해 역인덱싱() 기술을 사용한다.
전문 검색은 긴 문장의 String에서 부분 검색해서(SQL에 Like처럼) 수행하고, 역인덱싱은 긴 문장의 문자열을 분석해
작은 단위로 쪼개어 인덱싱 하는 기술이다(대표적으로 구글에서 역인덱싱을 사용) .
역인덱싱을 이용한 전문 검색에서 양질의 결과를 얻기 위해서는 문자열을 나누는 기준이 중요하며, 이를 지원하기 위해
엘라스틱은 3가지) 캐릭터 필터 , 토크나이저, 토큰 필터로 구성되어 있는 분석기 모듈을 갖고있습니다.
토큰과 용어
토큰(Token)과 용어(term)라는 단어는 엘라스틱에서 많이 사용 될 단어이자 헷갈릴수 있는 단어 이다보니, 여기서 짧게나마 용어를 정의하고 넘어가자.
예를 들어서 'noodle hot' 라는 문자열이 분석기를 거쳐서 인덱스에 저장된다고 가정할때, 분석기는 먼저 캐릭터 필터를 통해 원문에 불필요한 문자들을 제거한다(The, a, you)등등.... 이 과정에선 문자열 자체가 분리가 되지는 않는다.
토크나이저를 통해서 문자열이 필터링 되고 이때, 짤린 단어들은 토큰이라고 지칭한다('noodle','hot'). 이러한 토큰들은 복수의 토큰 필터를 거치며 정제되는데, 정제 후 최종으로 역인덱스에 저장되는 상태의 토큰들을 용어(term)이라고한다. (인덱스안에 2개의 다른 단어로 존재하게된다.)
토큰은 분석기 내부에서 일시적으로 존재하는 상태이고, 인덱싱되어 있는 단위, 또 검색에 사용되는 단위는 모두 용어라고 할 수 있다.
분석기 구성
| 구성요소 | 설명 |
| 캐릭터 필터 | 입력받은 문자열을 변경하거나 불필요한 문자들을 제거한다. |
| 토크나이저 | 문자열을 토큰으로 분리한다. 분리할 때 토큰의 순서나 시작, 끝 위치도 기록한다. |
| 토큰 필터 | 분리된 토큰들의 필터 작업을 한다. 대소문자 구분, 형태소 분석 등의 작업이 가능하다. |
- 캐릭터 필터 : 문자열의 전처리 작업
- 토크나이저 : 문자열을 토큰으로 분리
- 토큰 필터 : 분리된 문자열의 단어들이 필터를 거쳐 최종적으로 용어가 된다.
예) [가위 바위 보] 를 통해서 필터링하고 토크나이저를 하면 [가위][바위][보] 로 필터가 되어 인덱싱 되어 검색에 활용하게된다. 가위를 입력해도 [가위 바위 보] 를 출력 할 수 있다.
역인덱싱이란?
역 인덱싱이란 무엇일까? - 문자열을 토큰화하고 이를 인덱싱하는데 이 것을 역 인덱싱이라고 부릅니다.
많이 쓰이는 단어들을 선별해 그 단어가 몇 페이지에 나와 있는지 알려주는 것을 색인이라고 한다.
주로 책에 맨 뒷 페이지에 나와있는 경우가 많다.
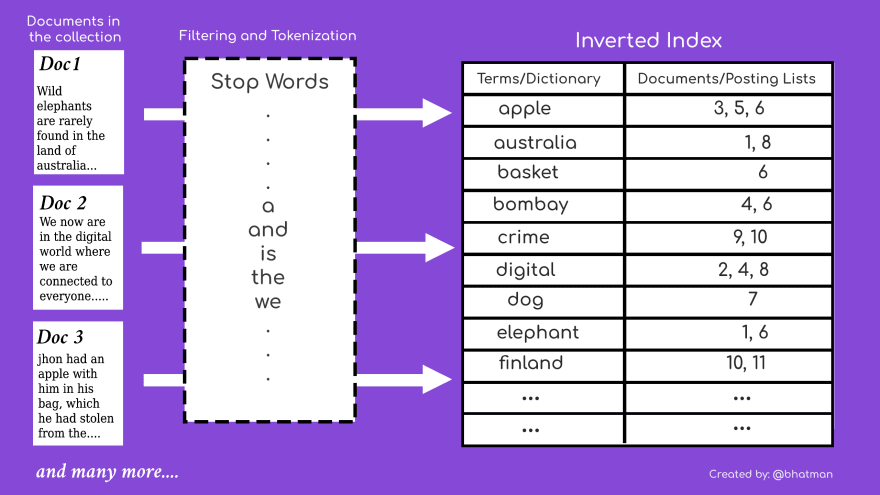
문서가 분석기를 거치면서 역인뎅싱 되고 있다. 분석기는 여러 필터와 토크나이저르 이뤄져 있는데 여기서는 스탠다느 토크나이저와 스톱필터, 소문자 변경필터, 스테이머 필터가 조홥된 분석기를 사용했다.
예를 들면 digital 이라고 치면 2,4,8의 문서에서 값을 찾아올수 있다.
분석기 API
엘라스틱 서치는 필터와 토크나이저를 테스트해볼 수 있는 analyze라는 이름의 REST API를 제공하고있다.
자세한 내용은 (https://www.elastic.co/guide/en/elasticsearch/reference/current/indices-analyze.html)에서 참고하시면 될거같습니다.
analyze API 사용법으 간단하다. analyzer에 원하는 분석기를 선택하고, text에 분석할 문자열을 입력하면 된다. 참고로, 스톱분석기는 소문자 변경 토크나이저와 스톱토큰 필터로 구성되어 있다.
예를 들어 the 10 most loving dog breed문장을 토큰화 하면 결과는 밑에 처럼 나온다.
{
"token":[
{"token":"most",......},
{"token":"loving",......},
{"token":"dog",......},
{"token":"breed",......},
]
}자 이제 분석기는 어떤식으로 토큰으로 분리하는지 알아봅시다.
분석기 종류
엘라스틱서치는 다양한 분석기를 제공합니다. 자주 사용되는 분석기는 standard,simple,whitespace,stop 이 있습니다.
| 분석기 | 설명 |
| standard | 특별한 설정이 없으면 엘라스틱서치가 기본적으로 사용하는 분석기이다. 영문법을 기준으로 한 스탠다드 토크나이저와 소문자 변경필터, 스톱필터가 포함되어 있다. [the,10, most,loving,dog,breeds] |
| simple | 문자만 토근화한다. 공백 숫자,하이픈(-)이나 작은따옴표(')같은 문자는 토큰화하지 않는다. [the,most,loving,dog,breeds] |
| whitespace | 공백을 기준으로 구분하여 토큰화한다. [The,10,most,loving,dog,breeds] |
| stop | simple 분석기와 비슷하지만 스톱 필터가 포함되어 있다. 스톱 필터의 의해 'the'가 제거 된다. [most,loving,dog,breeds] |
토크나이저
앞서 분석기는 반드시 하나의 토크나이저를 포함해야 한다고 설명했스빈다. 토크나이저는 문자열을 분히해 토큰화하는 역할을 합니다, 반드시 포함돼야 하기 때문에 형태에 맞는 토크나이저 선택이 가장 중요합니다.
대표적인 토크나이저를 알아보자.
| 토크나이저 | 설명 |
| standard | 스댄다드 분석기가 사용하는 토크나이저로, 특별한 설정이 없으면 기본 토크나이저로 사용된다. 쉼표나 점 같은 기호를 제거하며 텍스트 기반으로 토큰화한다. |
| lowercase | 텍스트기반으로 토큰화하며 모든 문자를 소문자로 변경해 토큰화한다 |
| ngram | 원문으로부터 b개의 연속된 글자 단위를 모두 토큰화한다. 예를들어 '엘라스틱서치' 를 [엘라,라스.스틱,틱서,서치]와 같이 연속된 두 글자를 모두 추출합니다. 사실상 원문으로부터 검색할 수있는 거의 모든 조합을 얻어낼수 있기 때문에 정밀한 부분 검색에 감정이 있지만, 토크나이징을 수행한 n개 이하의 글자 수로는 검색이 불가능하며 모든 조합을 추출하기 때문에 저정공간을 많이 차지 한다는 단점이 있다. |
| uax_url_email | 스탠다느 분석기와 비슷하지만 URL이나 이메일을 토큰화하는데 강점이 있다. |
다양한 토크나이저를 확인하는 곳: (https://www.elastic.co/guide/en/elasticsearch/reference/current/analysis-tokenizers.html)
필터
분석기는 하나의 토크나이저와 다수의 필터로 조합된다.
필터는 옵션으로 하나 이상을 포함할 수 있지만, 없어도 분석기를 돌리는 데 큰 문제는 없다.
대부분 엘라스틱에서 제공하는 분석기들은 하나 이상의 필터를 포함하고 있다
그 이유는 필터를 통해 더 세부적인 작업이 가능하기 때문입니다.
필터는 단독으로 사용할 수 없고 반드시 토크나이저가 있어야 한다.
캐릭터 필터
토크나이저 전에 위치하며 문자들을 전처리하는 역할을 하는데 HTML 문법을 제거/변경하거나 특정 문자가 왔을 때 다른 문자로 대체하는 일들을 한다. 예를들어 html 에서 공백이 오면 바꾸는 작업 등을 캐릭터 필터에서 진행하면 엄청 편하다.
캐릭터 필터를 사용하기 위해서는 커스텀 분석기를 만들어 사용하는것이 좋다.
토큰 필터
토크나이저에 의해 토큰화되어 잇는 문자들에 필터를 적용한다. 변경하거나 삭제하고 추가하는 작업이 가능하다.
토큰 필터는 종류가 많고 자주 변경되어서 버전마다 상이 하니 엘라스틱서치 웹페이지에서 확인하는것을 추천드립니다.
토큰필터에서 스탑필터는 주로 제거하는데 사용합니다. 크게 의미없는 'a','the','you' 와 같은 단어를 생각하시면 편할거같습니다.
아쉽게도 stop필터는 영어를 기반으로 하여서 한글에서는 작동이 잘 되지 않습니다. 다른 한글 분석기를 사용하시기 바랍니다.
stemmer 필터는 형태소를 분석해 어간을 분석하는 필터다 즉 언어마다 문법이 다르기 때문에 자기가 사용하는 언어에 맞는 필터를 사용해야하고 (영어기반입니다) 예시) live,living,lived 와 같은 단어를 어간이라고 하고 인식을 합니다.
커스텀 분석기 와 설정 방법
내장 분석기들 중 원하는 기능을 만족하는 분석기가 없을때 사용자가 직접 토크나이저 필터 등을 조합해서 사용할수 있는 분석기 입니다.
예를 들어 새로운 인덱스르 ㄹ하나 만들고 설정에 analysis파라미터를 추가하고 그 밑에 필터와 분석기를 만든다.
분석기 이름을 지정하고 타입은 custom 으로 지정하면 커스텀분석기를 의마한다.
분석기에는 반드시 토크나이저가 하나 들어가야 하는데 기본 스탠다드 토크나이저를 사용했고 캐릭터 필터는 사용하지 않았다.
아까 알게되었던 stop 필터에 값을 하나 넣고 text에 글을 넣으면 stop 필터값 을 제외하고 값들을 알게해줍니다.
필터 적용 순서
분석기에서 필터를 여러 개 사용한다면 필터의 순서에도 주의해야 한다. 필터 배열의 첫번째 순서부터 필터가 적용된다. 가끔 이 순서가 잘못되면 원하지 않는 결과가 나오기도 합니다.
예를 들면
filter : ["lowercase","my_stopwords"],
text : "Cats Lions Dogs"먼저 필터 첫번째 순서인 lowercase로 하면 Lions 가 lions으로 바뀌면서 내가 지정해놓은 stop필터 lions를 삭제시켜주지만
filter : ["my_stopwords","lowercase"],
text : "Cats Lions Dogs"이렇게 필터에 값을 바꿔버리면 어떻게 될까?
먼저 필터 첫번째 stop필터를 진행하는데 여기서 지정해놓은 lions는 text에 없어서 삭제를 하지 못하고 진행을 하게 됩니다. 값은 cats lions dogs 즉 lions가 문장에 포함되어 값이 나오게 됩니다.
이렇게 분석기에 대해서 알아보았습니다. 너무나 많은 api기능이 있기에 다 적지 못했습니다.
관련해서 더 많은 정보글을 보고싶으시다면 엘라스틱서치 홈페이지에서 보시면 될거같습니다.
https://www.elastic.co/guide/en/elasticsearch/reference/current/elasticsearch-intro.html
'Elasticsearch' 카테고리의 다른 글
| Elasticsearch - node repurpose tool to clean up (2) | 2023.02.27 |
|---|---|
| elasticsearch 클러스터간 검색 (1) | 2023.02.25 |
| elasticsearch 백업/복원 (클러스터간 백업/복원) (1) | 2023.02.25 |
| 엘라스틱서치 - BULK (0) | 2022.10.06 |
| 엘라스틱서치의 기본요소 (0) | 2022.10.05 |