Cluster lever shard allocation

샤드 할당은 initial recovery, replica 할당(증설), 재할당 그리고 노드가 추가/삭제 될때 발생 하는 것에 대한 설정들은 다음과 같습니다.
- All
- Primaries
- New_primaries
- None
이 Setting은 노드 재시작시 local Primary shard 복수 시에는 해당하지 않습니다.
Local primaries 란 remote cluster의 primaries가 아닌 것을 말합니다. ( remote cluster)
예시) Primary 샤드를 갖고 있는 노드가 재시작하면 재시작된 노드의 primary shard allocation id와 active인 allocation id를 비교해서 같다면 바로 primary로 즉시 복구 합니다.
cluster.routing.allocation.node_concurrent_incoming_recoveries
cluster.routing.allocation.node_concurrent_outcoming_recoveries
동시에 샤드 복구를 허용하는 개수, 두 설정 모두 default가 2
incoming 은 샤드 rebalance 가 아니라면 대부분 replica 샤드이고 outgoing은 샤드 rebalance가 아니라면 대부분 primary 샤드 입니다.
Cluster.routing.rebalance.enable – 재분배가 가능한 샤드의 종류 (all, primaries, replicas, none) Cluster.routing.allocation.allow_rebalance – 샤드 재분배를 허용하는 경우,
Always
Indices_primaries_active: 모든 primary 샤드가 클러스터에 할당된 경우
Indices_all_active(default): 모든 샤드가 할당된 경우
Cluster.routing.allocation.cluster_concurrent_rebalance : 동시에 재분배할 샤드 갯수
Shard balancing heuristics
아래 설정 값은 각 샤드를 할당할 노드를 선택할 때 위에 소개한 설정과 함께 사용됩니다.
위 3개의 rebalancing setting값에서 (rebalance 문자가 있는 설정값) 허용된
rebalance 작업이 더 이상 balance.threshold 값보다 높일 수 없다고 판단되면 해당 클러스터는 균형을 이루었다고 판단하고
재분배가 안 일어날 수도 있습니다.
전체 샤드 개수 중 해당 노드에 할당된 샤드 개수의 weight factor
Default는0.45f 값을 높일수록 노드당 갖고 있는 샤드 개수가 비슷해집니다.
특정 노드에 할당된 인덱스 당 샤드 개수의 weight factor
Default는0.55f 값을 높일수록 노드당 갖고 있는 인덱스 개수가 비슷해집니다.
재분배 일어날 최솟값
Default는 1.0f 값을 높일수록 재분배에 덜 민감하게 동작합니다.
노드마다 가중치 계산하고 threshold
Balancing algorithm에 의해 재분배를 하려고 해도 forced awareness, allocation filtering에 의해 재분배가 일어나지
않을 수도.
문제점 :

인덱스의 데이터값이 들어올때 primary shard의 할당이 한 노드에 쏠리는 현상을 어떤식으로 방지하거나 혹은 할당된 프라이머리샤드를 재분배를 할 수 있는지.
Disk-based shard allocation

노드에 사용 가능한 디스크를 고려해서 샤드를 할당할 수도 있습니다.
샤드 할당 시 고려할 disk low watermark, default 85%
예) 85%로 설정하면 디스크 사용율이 85%인 노드에는 샤드 할당을 하지 않습니다.
이 설정은 새로 생기는 인덱스의 primary 샤드엔 적용되지 않습니다.
값을 비율로 할 수도 있고 (ex 85%) 절댓값으로도 (500mb) 할 수 있습니다.
비율로 할 때는 사용량을 의미하고, 절대값으로 할 때는 남는 공간을 의미합니다.
넘치는 단계로 판단하는 watermark, default 95%
A 노드의 디스크 사용률이 95%가 넘으면 A노드에 할당된 샤드의 인덱스들은 (한 개의 샤드여도) read-only index block 이 됩니다.
인덱싱이 가능한 디스크 공간이 생기면 (수동으로) 수동으로 index block 설정을 수동으로 해제해야 합니다.
read_only, read_only_allow_delete block 설정된 인덱스마다 들어가서 수동으로 해제
위 3 개의 설정값은 비율과 절댓값을 섞어 쓸 수 없습니다.
(low watermark – 85% / high watermark 500mb를 같이 사용 X)
내부적으로 low < high, high < flood_stage

Cluster.info.update.interval 각 노드의 디스크 사용량 정보 업데이트 간격, default 30
Cluster.routing.allocation.disk.include_relocations 노드의 디스크 사용량을 계산할 때 노드의 재배치 중인 샤드 고려 여부,
default true 재배치 중인 샤드의 크기를 고려한다는 의미는 한 샤드의 재배치가 90% 정도 진행 중일 때
디스크 사용량을 조회하면 이미 재배치가 완료된 것처럼 디스크 사용량이 계산됩니다.
Cluster-level shard allocation and routing settings | Elasticsearch Guide [8.17] | Elastic
You can’t mix the usage of percentage/ratio values and byte values across the cluster.routing.allocation.disk.watermark.low, cluster.routing.allocation.disk.watermark.high, and cluster.routing.allocation.disk.watermark.flood_stage settings. Either all va
www.elastic.co
Shard allocation awareness
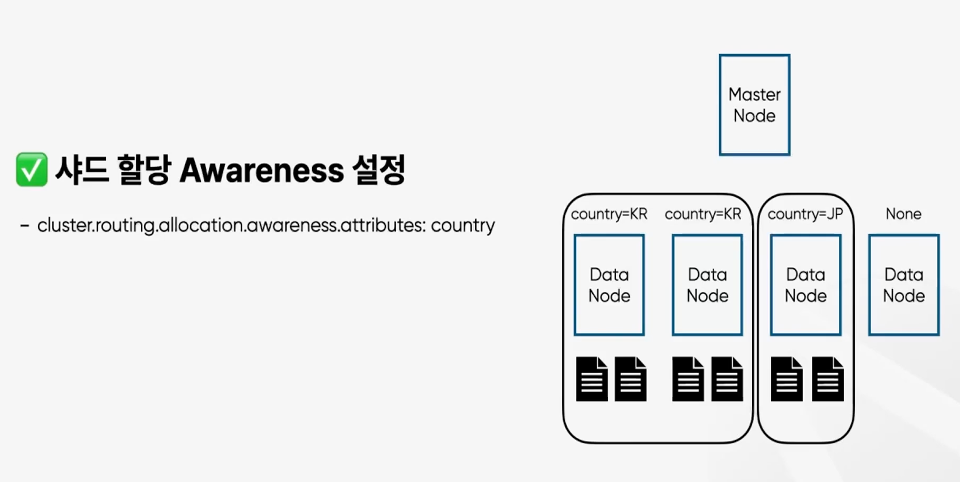
물리적인 거리를 고려해서 shard 할당할 수 있습니다. ‘rack_id’와 ‘zone’ attribute를 이용할 수 있습니다.
https://github.com/elastic/elasticsearch/blob/master/server/src/main/java/org/elasticsearch/cluster/routing/alloc
Attribute 값의 개수만큼 샤드를 복사합니다.
Force awareness
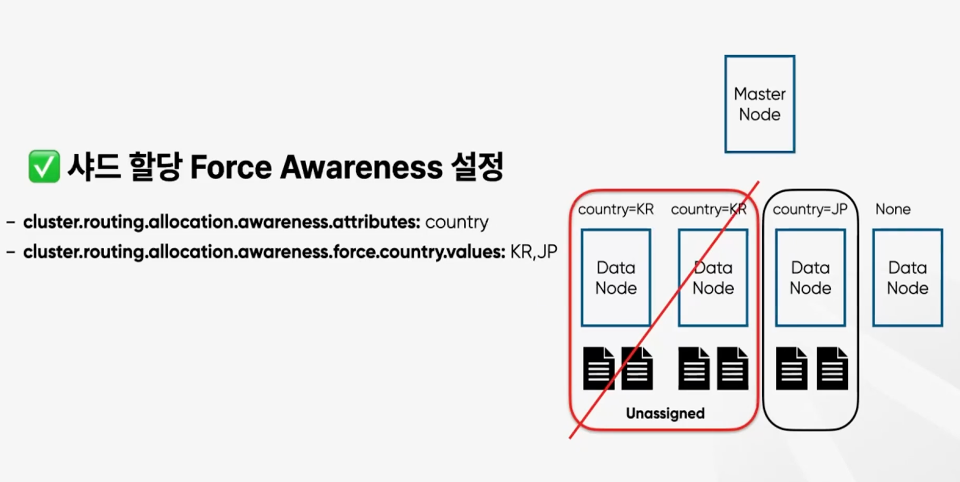
Shard allocation awareness 기능을 이용하여 근거리에 샤드를구성할 수 있습니다.
전 세계에 서비스가 되는데 동일한 데이터 조회가 필요한 경우에 쓰임이 많을것으로 생각됨
Elasticsearch cluster 내 node 들에 primary shard와와 replica shard 할당하는 방법 결정
Cluster-level shard allocation filtering
특정 노드를 shutdown 시키려고 할 때 해당 기능을 이용하면 좋습니다.
Filtering 할수 있는 attribute는node name, host IP, publish IP , IP(host or public IP), hostname, node id가 있습니다.
예시) Node 42_1번의번의 disk 가 90% 이상 사용 중인 경우
신규 인덱스의 샤드를배치시키게 되면 disk full로 이어질 수 있음.
이런 경우 당장 shard rebalancing을 수행하기 어렵고
다른 노드들에 disk usage가 여유가 있을 경우 임시로 제외시키는 설정 가능
-> 장애로 이어지기 전에 조치를 취하고 disk 용량을 확보 후 다시 투입
'Elasticsearch' 카테고리의 다른 글
| ElasticSearch, 오픈 소스로의 귀한! (0) | 2025.02.20 |
|---|---|
| 엘라스틱서치의 마스터 후보 노드 및 캐시 (0) | 2024.12.28 |
| 엘라스틱서치 - 장애 복구 작업 도중 새 인덱스 생성될 때 (0) | 2023.10.04 |
| 엘라스틱서치 - 샤드 운영전략 (0) | 2023.10.01 |
| 엘라스틱서치 - 대량 색인이 필요할 때 (0) | 2023.10.01 |