오늘은 JPA N+1의 문제 해결에 대해서 글을 공유해드리려고 합니다.
* Java 백엔드 개발자를 위한 데이터베이스 쿼리 최적화에 적합한 내용입니다.
개발자가 직면하는 가장 일반적인 성능 병목 현상 중 하나가 N+1입니다.
애플리케이션이 단 한 번의 쿼리로 동일한 결과를 얻을 수 있는데도 N+1번의 데이터베이스 쿼리를 수행할 때 발생합니다.
과도한 데이터베이스 Hit는 느린 응답 시간, 높은 서버 부하, 열약한 사용자 경험으로 이어질 수 있습니다.
원인을 함께 파악해 보고 개발자가 이러한 문제를 어떻게 완화할지에 대해서 다양한 전략과 기법에 대해서 적어보겠습니다.
앞서, N+1 문제가 무엇인지 알아보도록 하겠습니다.
N+1 문제란 무엇인가?
애플리케이션이 개체목록(예시: 제품, 사용자 또는 게시물 목록)을 가져온 다음 목록의 각 객체애 대해 추가 데이터베이스 쿼리를 수행하여 관련 데이터를 검색할 때 발생을 하게 됩니다.
예를 들어 작성자 정보와 함께 블로그 게시물 목록을 표시하는 Java 애플리케이션을 생각해 보자.
애플리케이션이 글 목록을 가져온 다음 각 글의 작성자 정보를 검색하기 위해 별도의 쿼리를 수행하면 N+1 쿼리가 발생하며, 여기서 N은 글의 수입니다. 이러한 비효율적인 쿼리 패턴은 많은 수의 데이터베이스 HIT로 빠르게 이어질 수 있습니다.
N+1 문제 원인
1. 지연 로딩(Lazy Loading) :
수많은 Java ORM 프레임워크들, 가령 Hibernate에서 기본적으로 지연 로딩을 사용합니다.
지연 로딩이란 관련된 데이터를 가져올때만 데이터베이스에 가져오는 것을 의미합니다. 개발자가 컬렉션의 각 항목에 대한 관련 데이터에 접근할 때 N+1 쿼리를 발생할 수 있습니다.
2.비효율적인 쿼리(Inefficient Queries)
개발자는 관련 데이터를 반복해서 가져오는 코드를 작성하여 최적화된 단일 쿼리로 충분할 수 있는 데이터베이스 쿼리를 여러 번 수행하게 될 수 있습니다.
3. 일괄 가져오기 부족 (Lack of Batch Fetching)
일부 ORM 프레임워크에서 제공하는 기술인 일괄 가져오기를 사용하면 단일 쿼리에서 여러 개체에 대한 관련 데이터를 검색할 수 있습니다.
개발자들은 이 기능을 간과하거나 오용하는 경우가 많습니다.
N+1 문제를 완화하기 위한 전략들
N+1 문제를 해결하고 과도한 데이터베이스 히트를 최소화하기 위해 Java 백엔드 엔지니어는 다양한 전략과 모범 사례를 활용할 수 있습니다
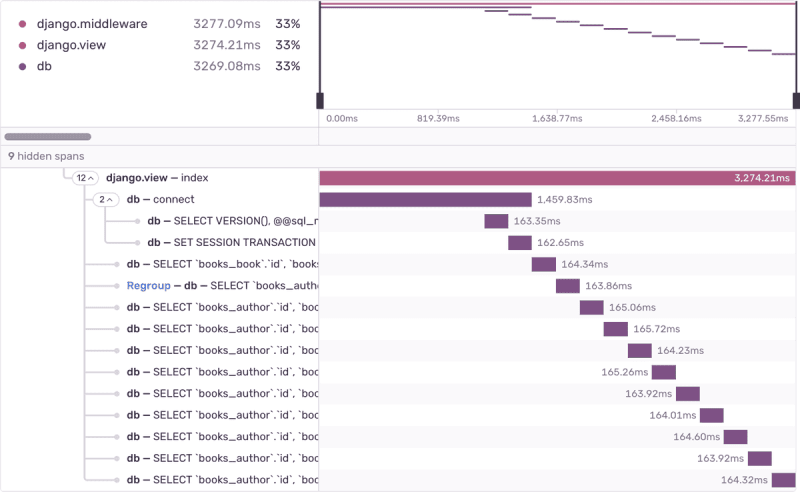
1. 에저 로딩
에지 로딩을 사용하면 관련 데이터를 미리 불러와 추가 쿼리의 필요성을 줄일 수 있습니다. 대부분의 ORM 프레임워크는 관련 데이터를 로드할 시기와 방법을 지정하는 메커니즘을 제공하므로 데이터베이스 쿼리를 최적화할 수 있습니다.
2. 일괄 가져오기
ORM 프레임워크에서 제공하는 일괄 가져오기 기능을 사용하여 관련 데이터를 하나씩 가져오지 않고 일괄적으로 검색하세요. 이렇게 하면 데이터베이스 쿼리 횟수를 크게 줄일 수 있습니다.
3. DTO 투영
데이터베이스에서 필요한 데이터만 가져오려면 DTO(데이터 전송 객체) 투영을 사용하는 것이 좋습니다. 이 접근 방식을 사용하면 검색되는 데이터의 양을 최소화하여 쿼리 속도를 높일 수 있습니다.
4. 캐싱
캐싱 메커니즘을 구현하여 자주 액세스하는 데이터를 메모리에 저장하세요. 캐싱은 반복적인 데이터베이스 쿼리의 필요성을 줄여 응답 시간을 개선하고 데이터베이스 부하를 줄이는 데 도움이 될 수 있습니다.
5. 페이지 매김 및 필터링
페이지 매김 및 필터링을 구현하여 단일 쿼리에서 검색되는 레코드 수를 제한하세요. 이는 대규모 데이터 세트를 다룰 때 특히 유용할 수 있습니다.
6. 쿼리 최적화
데이터베이스 쿼리를 정기적으로 검토하고 최적화하세요. 쿼리 실행 계획을 분석하고 데이터베이스 프로파일링 도구를 사용해 성능 병목 현상을 파악하고 해결하세요.
마치며
N+1 문제와 과도한 데이터베이스 히트는 Java 백엔드 엔지니어가 직면하는 일반적인 성능 문제입니다. 개발자는 N+1 문제의 원인을 이해하고 일괄 로딩, 배치 가져오기, DTO 예측, 캐싱, 페이지 매김 및 쿼리 최적화와 같은 효과적인 전략을 채택함으로써 애플리케이션의 성능을 크게 향상해 원활한 사용자 경험을 보장하고 서버 부하를 줄일 수 있습니다. N+1 문제를 해결한다는 것은 단순히 데이터베이스 쿼리를 최적화하는 것만이 아니라 사용자에게 효율적이고 확장 가능한 백엔드 솔루션을 제공하는 것입니다.
'DB' 카테고리의 다른 글
| Database Lock 이란? (1) | 2024.06.18 |
|---|---|
| PL/SQL 이란 (0) | 2022.01.10 |
| 데이터베이스 모델링 -1 (0) | 2022.01.07 |
| SQL 사용자 권한 (0) | 2022.01.05 |
| SQUENCE INDEX(순차 적으로 증가하는 값) (0) | 2022.01.05 |











